Vectors in Oracle¶
Cymbal Coffee stores product descriptions as 3072-dimension vectors next to
their text columns. A VECTOR_DISTANCE(..., COSINE) query, served by an
HNSW index, returns the closest products straight from the same database
that holds the rest of the catalog.
flowchart LR
Q[query embedding<br/>3072 floats] --> H[(HNSW NEIGHBOR GRAPH<br/>in SGA)]
H --> S["VECTOR_DISTANCE<br/>(embedding, :q, COSINE)"]
S --> R[top-k product rows]
At a glance¶
Setting |
Value |
|---|---|
Embedding model |
Vertex AI |
Dimensions |
|
Storage |
|
Distance metric |
|
Index type |
HNSW, |
Query embedding input |
Query-purpose instruction + user text |
Document embedding input |
Document-purpose instruction + product text |
The product table and the embedding cache both use the same shape.
Schema annotations¶
The baseline DDL also annotates the vector columns with their application
contract: model, dimension count, embedding purpose, and distance metric. These are
Oracle 26ai schema annotations, so they live with the database metadata and can
be queried from USER_ANNOTATIONS_USAGE after coffee upgrade.
embedding VECTOR(3072, FLOAT32)
ANNOTATIONS (
Display 'Product embedding',
Embedding_Model 'gemini-embedding-2',
Embedding_Dimensions '3072',
Embedding_Purpose 'document',
Distance 'COSINE'
),
The HNSW index¶
The index is created in the baseline SQLSpec migration alongside the
product table — running coffee upgrade applies it before any fixtures
load.
CREATE VECTOR INDEX product_embedding_idx ON product (embedding)
ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE COSINE
WITH TARGET ACCURACY 95
PARAMETERS (TYPE HNSW, NEIGHBORS 40, EFCONSTRUCTION 500);
NEIGHBORS=40 and EFCONSTRUCTION=500 are sensible defaults for a catalog
on the order of a few thousand rows. WITH TARGET ACCURACY 95 lets Oracle
pick the search-time ef that meets the recall target.
Vector memory¶
HNSW INMEMORY indexes need a non-zero vector_memory_size allocation
before the index DDL runs. Without it migrations fail with ORA-51962.
ALTER SYSTEM SET vector_memory_size = 512M SCOPE = SPFILE;
512M is intentional for Oracle Free Edition’s constrained SGA. The committed
demo fixture has 130 product vectors, so this is generous headroom for the
catalog plus query embeddings saved in embedding_cache. For larger Oracle
editions, raise vector_memory_size to a 4G target on the SPFILE.
Verify the pool with:
SELECT name, bytes FROM v$sgainfo WHERE name = 'Vector Memory';
The query shape¶
The vector search itself is a named SQL file the products service loads by
key — every query in the app lives under src/app/db/sql/.
-- name: vector-search-products
SELECT id,
name,
description,
price,
1 - VECTOR_DISTANCE(embedding, :query_vector, COSINE) AS similarity_score
FROM product
WHERE 1 - VECTOR_DISTANCE(embedding, :query_vector, COSINE) > :threshold
ORDER BY similarity_score DESC
FETCH FIRST :limit ROWS ONLY;
1 - VECTOR_DISTANCE(..., COSINE) flips distance into a similarity score
where higher is better. :threshold filters out rows that aren’t close
enough; :limit caps the top-k.
ProductService.search_by_vector is the SQLSpec async service method that
runs the query above and maps each row to a typed ProductMatch — Python
hands Oracle a plain list[float], no manual packing required.
async def search_by_vector(
self,
query_embedding: list[float],
similarity_threshold: float = 0.7,
limit: int = 5,
*,
store_id: int | None = None,
) -> list[ProductMatch]:
sql_key = "vector-search-products-by-store" if store_id is not None else "vector-search-products"
binds: dict[str, Any] = {"query_vector": query_embedding, "threshold": similarity_threshold, "limit": limit}
if store_id is not None:
binds["store_id"] = store_id
return await self.driver.select(db_manager.get_sql(sql_key), **binds, schema_type=ProductMatch)
SQLSpec and the Oracle adapter handle the vector binding. Don’t reach for
array.array("f", ...).
Embedding cache¶
User queries are repeated often. The same text + model hashes to the same
row in embedding_cache, which stores the vector itself in a parallel
VECTOR(3072, FLOAT32) column. Cache hits skip the Vertex AI call entirely
and feed straight into the HNSW search.
Understanding performance¶
The /explore page surfaces three timings per query:
Click to expand Explore Page Screenshot
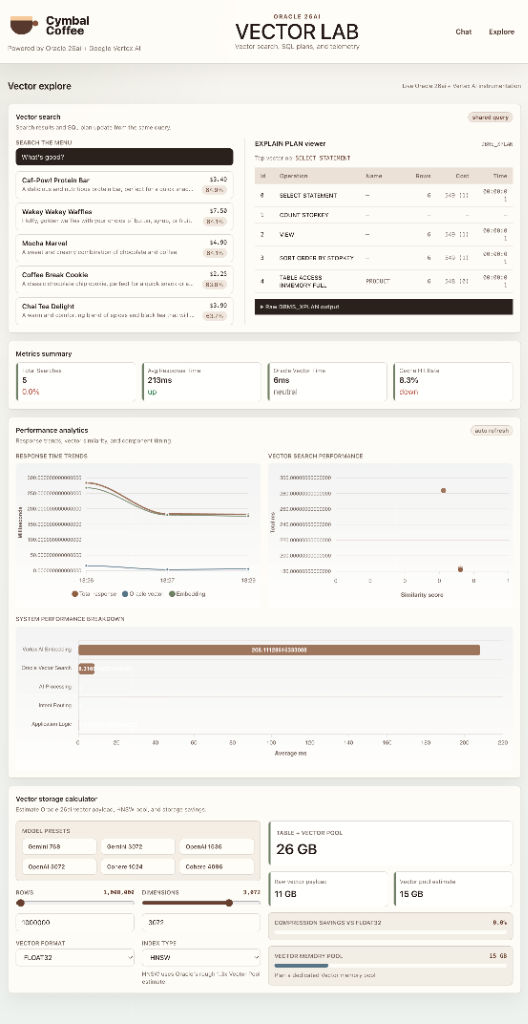
embedding_ms — time spent generating (or hitting the cache for) the query vector;
oracle_ms — round-trip time for the HNSW search;
similarity score — the top returned row’s score.
If oracle_ms spikes, check that vector_memory_size is non-zero, that
product_embedding_idx exists, and that the query metric still matches
COSINE.
Where this is used¶
The walkthrough stitches embedding + HNSW search into one chat message: see the walkthrough.
RAG uses the
ProductMatchrows returned here as grounding context: see RAG.Chat routing decides whether to fire this search at all: see Chat routing and Google ADK.